The industry is converging on skills.
An agent skill is a natural-language document that tells a model how to handle a specific task. What tools to call. What constraints to respect. What good looks like. Call them skills, runbooks, playbooks. The name varies. The pattern doesn't.
The ecosystem around skills is maturing fast. You no longer need to handwrite them. Frameworks automate generation from domain context, optimize text against evaluation data, validate through quality gates, extract new skills from production traces, and feed everything back into a loop. The lifecycle is closing.
This works. With 5 skills, 10, maybe 15, you can load everything into context and the model handles it. Picks the right one. Executes cleanly. Moves on.
Then you scale. And scaling breaks it. Not dramatically. Not with an error message. Quietly. The model still runs. It just stops being good.
What if I told you that solving this problem doesn't just fix the degradation, it makes the skill layer use 6.3% of the tokens it used before? Same model. Same skills. A much cleaner context. If that sounds interesting, keep on reading.
When More Became Less
I have 31 skills in my harness. Email monitoring. Blog writing. Memory consolidation. Research workflows. Code delegation. Each one is a markdown file: instructions, examples, constraints, trigger conditions.
They all load at startup. The model sees all 31 simultaneously. And still it forgets to use them.
Not all of them. Not always. But consistently enough to notice. I ask for a draft and the writing voice skill doesn't activate. I request meeting notes and the process-meeting skill doesn't fire. The skills are there, in context, loaded and available. The model just doesn't reach for them. I have to say: "Use the writing skill, please."
The skills hadn't gotten worse. There were just too many of them competing for the model's attention.
And I have a growing concern. Context windows keep growing. Models offer 200K, 500K, a million tokens. The instinct is to fill them. But compute isn't free, frontier models are getting more expensive (not less), and agent workloads consume tokens at a rate no one planned for. Efficiency isn't a nice-to-have anymore. It's the constraint that separates agents that scale from agents that plateau.
Attention is Finite. And Costly.
Transformer attention is not free. Every token in context competes for the model's focus. Load all your skills at once, and you've put fifty speakers in a room where the model is trying to hear one.
Attention pollution. The model's attention distributes across everything in context. More irrelevant definitions means less focus on the relevant one. Quality degrades proportionally to the noise around it.
Context bloat. Every token costs compute. A well-written skill runs 2,000 to 5,000 tokens. Fifty of those: 100K to 250K tokens spent before the user has said a word. You're paying for noise.
Both invisible at demo scale. Both compound at production scale.
The Room, Not the Speech
I went looking for who's solving this. What I found: paper after paper on skill optimization. SkillOpt (Microsoft) treats skill text as a trainable parameter and runs gradient-style edits. SkillGrad uses trajectory diagnostics to propose targeted rewrites. Ctx2Skill uses multi-agent self-play to discover skills from raw context.
Better generation. Better validation. Better evolutionary search over skill text. Everyone is perfecting the speech.
But some are working on the room.
Anthropic's Tool Search Tool lets Claude dynamically discover and load tools on demand via search instead of packing thousands of definitions into context upfront. It solves context bloat for tool schemas. It doesn't touch behavioral skills, voice, or process instructions.
SkillRouter (March 2026) is a 1.2B-parameter retrieve-and-rerank pipeline that routes queries to the right skill from pools of 80,000+. Academic validation that retrieval beats brute-force loading. But it's a research benchmark, not a production system. No measured impact on output quality over time.
Agentic Proposing (February 2026) uses a specialized agent to dynamically compose modular reasoning skills from a library during problem-solving, hitting 91.6% on AIME 2025. Powerful for math and logic. Silent on the messy, ambiguous skills that govern how an agent writes, triages, or remembers.
The pattern is converging. Don't load everything. Retrieve what's relevant.
The fix isn't a better speech. It's amplifying the right signal.
Introducing Skiller
A static harness loads skills at session start. All of them, or a fixed subset. It works when the set is small and intent is predictable. It breaks the moment either condition changes.
A dynamic harness retrieves skills at runtime. It treats the skill registry not as a config file, but as a knowledge base to search. The difference is architectural:
Static: Skill registry → load all → execute.
Dynamic: User message → interpret intent → retrieve relevant skill(s) → load only those → execute.That's Skiller. A dynamic skill retriever for your agent harness.
The model sees only what it needs. Attention stays focused. Context budget goes to the task. Output quality holds regardless of how many skills exist in the registry.
The mechanism:
- Every skill carries metadata: a description, trigger conditions, domain tags.
- Descriptions are embedded and indexed (same infrastructure that handles memory and documents).
- At query time, the user's message is matched against skill descriptions. Hybrid search: keywords for precision, vectors for intent, re-ranking for final selection.
- Top match loads. Everything else stays out.
Retrieval takes milliseconds. The cost of not doing it: degraded output, wasted tokens, an agent that knows too much and executes too little.
The moment I switched from "load all 31" to "retrieve the right 1 or 2," quality jumped back to where it was with five skills. The skills hadn't changed. The context had.
Early Results (Updated June 19, 2026)
Skiller is in production daily. Not for tool schemas or math reasoning, but for behavioral skills. Writing voice. Meeting processing. Email triage. Memory consolidation. The kind of skills that shape how an agent acts, not just what it calls.
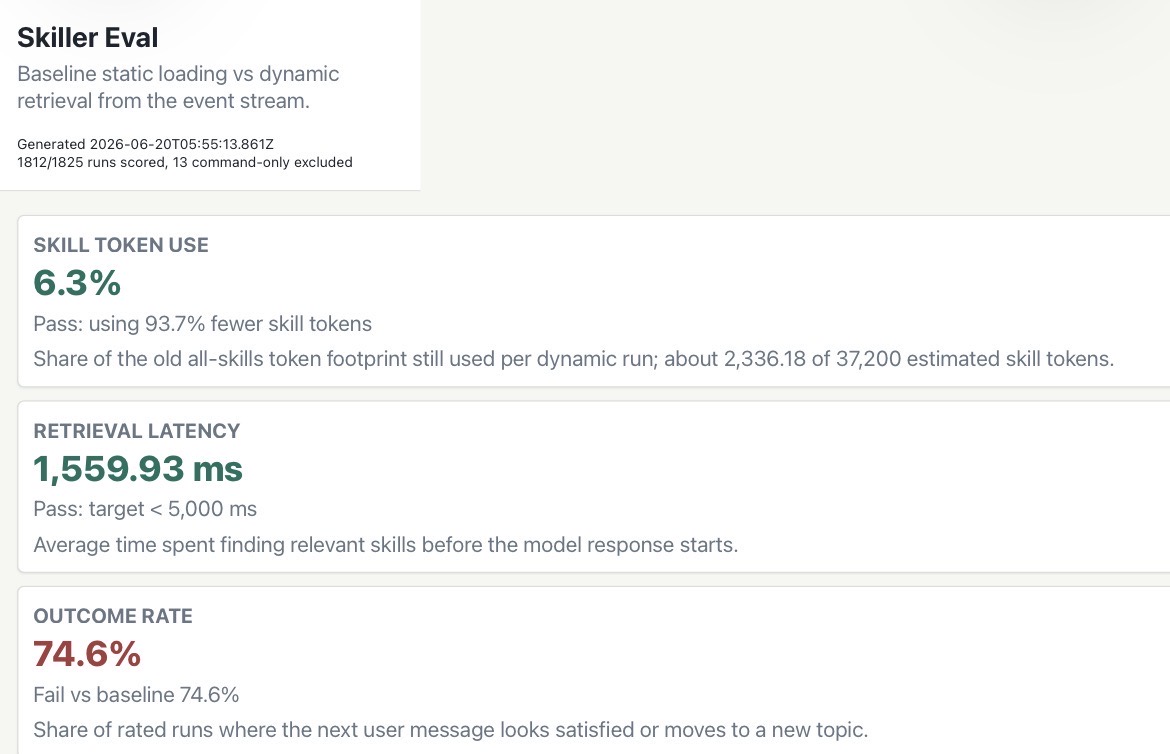
Updated results from 1,812 scored runs: 233 dynamic experiment runs against a 1,579-run static baseline, with 13 command-only runs excluded:
- Skill token use: 6.3% of the old all-skills footprint per dynamic run. Put differently: Skiller is reducing skill-loading tokens by 93.7%.
- Retrieval latency: 1.56 seconds on average to find the relevant skill before the model response starts.
- Outcome quality: 74.57% success rate (dynamic) vs. 74.61% (static). Measured quality is effectively flat while the context gets much smaller.
The math is cleaner now: the old all-skills footprint was estimated at 37,200 skill tokens. Dynamic retrieval is using about 2,336 skill tokens per run. That compresses the skill-loading slice by roughly 15.9x.
That does not mean the whole subscription does 15.9x more work. Conversation history, tool output, files, and the model's own reasoning still take context. But it does mean the skill layer stops being the thing that fills the room. The same budget can support longer sessions, more specialized skills, and more useful work before context becomes the constraint.
For a team or enterprise harness with dozens of skills and hundreds of users, the numbers compound fast.
That's what Skiller gives you. Not just a fix for the degradation. A harness that does more with less.
The Principle
One right skill in a clean context will outperform twenty perfect skills in a crowded one.
The quality of an agent's output is bounded by the signal-to-noise ratio of its context. Not by the model. Not by the skill. By what surrounds the skill when it runs.
Don't optimize the skill. Optimize the context. Amplify the right signal.
Ideas are my own. Co-written with AI.